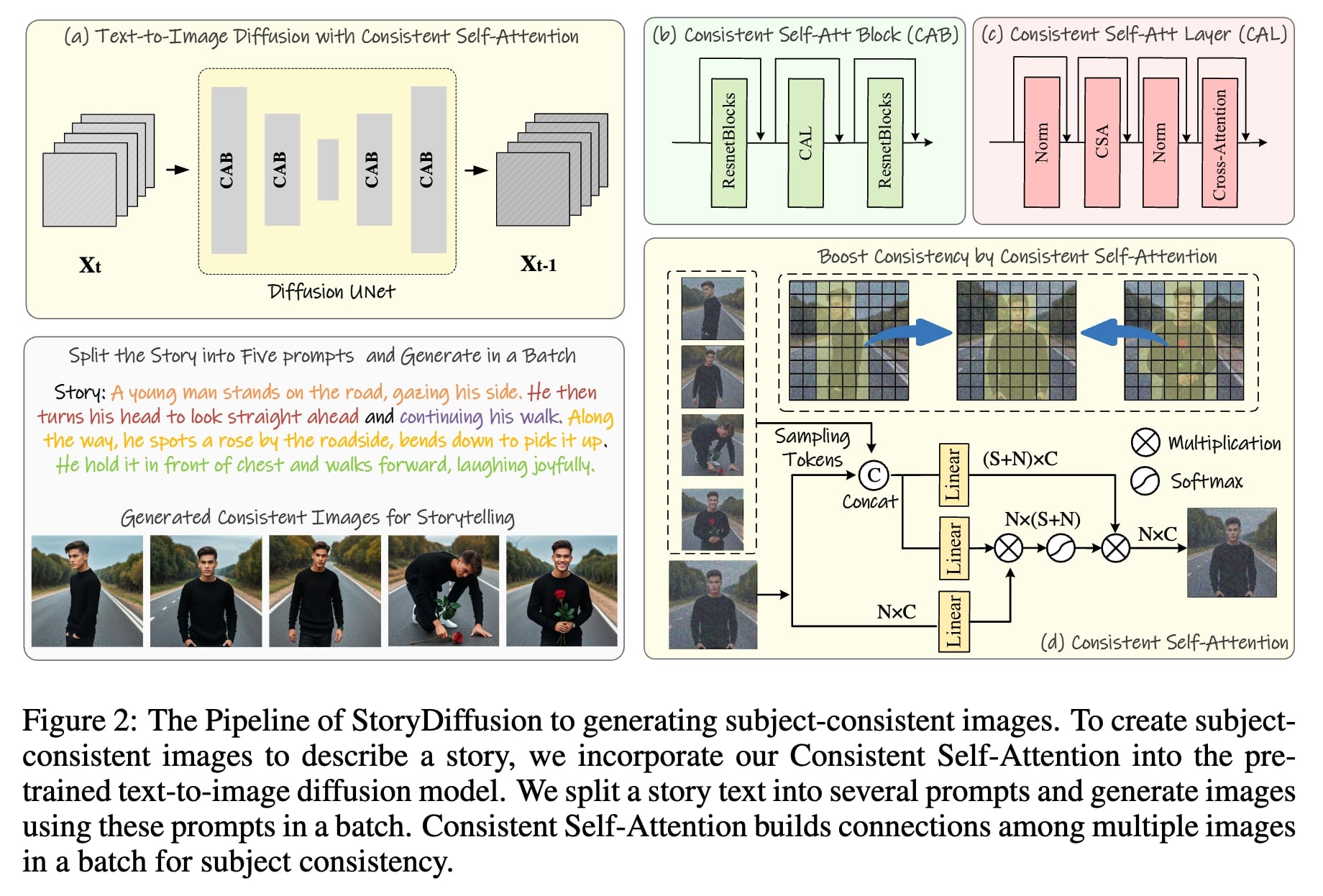
StoryDiffusion can create impressive comics by our consistent self-attention, maintain character consistency for cohesive storytelling.
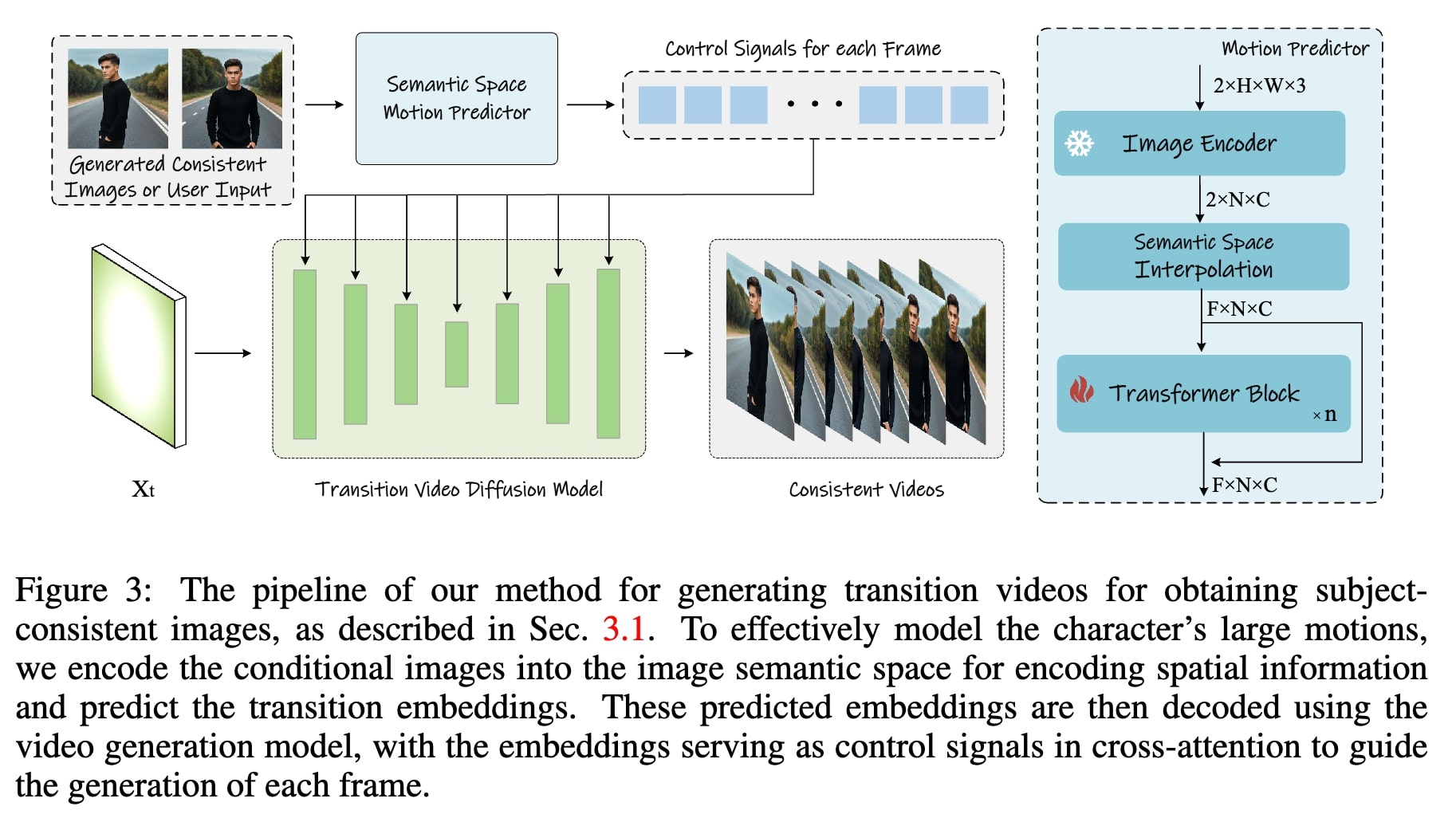
Video Generation Results
StoryDiffusion can generate high quality video by our image semantic motion perdictor with our generated consistent images or user-input images as condition.
Video Gallery
Using images generated by our consistent self-attention
Using images generated by our consistent self-attention
Using Condition images from SORA
Using User-Input Condition images
Using User-Input Condition images
Using User-Input Condition images
Using User-Input Condition images
Using User-Input Condition images
Using User-Input Condition images
Using User-Input Condition images
Using User-Input Condition images
Using images generated by our consistent self-attention
Using images generated by our consistent self-attention
Using images generated by our consistent self-attention
Using images generated by our consistent self-attention
Using images generated by our consistent self-attention
Using images generated by our consistent self-attention
Using Condition images from SORA
Using User-Input Condition images
Using User-Input Condition images
Using User-Input Condition images
Using User-Input Condition images
Using User-Input Condition images
Using User-Input Condition images
Using User-Input Condition images
Using User-Input Condition images
Using images generated by our consistent self-attention
Using images generated by our consistent self-attention
Using images generated by our consistent self-attention
Using images generated by our consistent self-attention
Using images generated by our consistent self-attention
Using images generated by our consistent self-attention
Using Condition images from SORA
Using User-Input Condition images
Using User-Input Condition images
Using User-Input Condition images
Using User-Input Condition images
Using User-Input Condition images
Using User-Input Condition images
Using User-Input Condition images
Using User-Input Condition images
Using images generated by our consistent self-attention
Using images generated by our consistent self-attention
Using images generated by our consistent self-attention
Using images generated by our consistent self-attention
Using images generated by our consistent self-attention
Using images generated by our consistent self-attention
Using Condition images from SORA
Using User-Input Condition images
Using User-Input Condition images
Using User-Input Condition images
Cartoon characters generation
StoryDiffusion can also create amazing consisitent cartoon characters images.
Multiple Characters Generation
StoryDiffusion can also maintain the IDs of multiple characters at the same time and generate consistent images.
More Comic Generation Example
StoryDiffusion can create impressive comics. We will add more comics and put on here.